Le but de ce TD est d'approfondir les utilisations des parcours en profondeur. Il est nécessaire d'avoir traité les deux premiers exercices du TD 01. Le minimum à faire en deux heures est l'un des deux exercices suivants au choix. Le deuxième est nettement plus difficile que le premier.
Il s'agit ici de construire une version orientée du graphe du jeu de la lettre qui saute (TD 01) et d'en calculer un tri topologique. Les fonctions demandées ici sont légèrement différentes de celles du cours.
Pour obtenir un graphe orienté, on considère qu'un mot
a a un mot b pour successeur
s'ils ne diffèrent que d'une lettre et si la lettre
de a qui diffère est plus petite que la lettre
de b correspondante. Ce graphe définit
une sorte de dictionnaire où la définition d'un mot est
sa liste de successeurs. Le but de l'exercice est
d'écrire le dictionnaire (c'est à dire chaque mot
et sa définition) de sorte que les mots utilisés dans
la définition aient déjà été définis précédemment.
Un tel ordre est l'inverse d'un tri topologique
(dans un tri topologique, chaque mot doit apparaître avant
ses successeurs).
Modifier
lettreQuiSaute ()
et éventuellement ajouterArete () pour qu'un
mot d'indice d ne soit rajouté à la liste de
successeurs d'un mot d'indice s que si les
deux mots ne diffèrent que d'une lettre et si la lettre par
laquelle le mot d'indice d
diffère est plus grande que celle de du mot
d'indice s.
On dira indifféremment que le mot d'indice d
est successeur de celui d'indice s ou que
le mot d'indice d apparaît dans la définition de
celui d'indice s. On pourra modifier
diffUneLettre () ainsi :
static boolean diffUneLettre (String a, String b) {
// a et b supposes de meme longueur
int i=0 ;
while (i<a.length () && a.charAt (i) == b.charAt (i))
++i ;
if (i == a.length ())
return false ;
if (a.charAt (i) > b.charAt (i))
return false ; // version orient'ee
++i ;
while (i<a.length () && a.charAt (i) == b.charAt (i))
++i ;
return i == a.length () ;
}
Un cycle est une suite circulaire de mots telle qu'un mot a toujours le mot suivant dans sa définition. Si jamais le graphe possède un cycle, il ne sera pas possible d'écrire le dictionnaire de sorte qu'un mot apparaissant dans une définition soit toujours défini auparavant. Nous allons donc tout d'abord tester si le graphe contient des cycles.
Écrire une fonction static boolean dfsCycle (Graphe g, int
x) qui parcourt en profondeur à partir de x et
renvoie true si un cycle est atteignable à partir
de x, c'est à dire s'il existe un chemin
partant de x qui boucle sur lui-même.
Pour cela on pourra
utiliser un tableau de booléens visiteEnCours
pour marquer les sommets dont la visite est en cours,
c'est à dire dont l'appel à dfsCycle
est en cours d'exécution.
Remarquons que la suite d'appels récursifs en cours correspond à un chemin dans le graphe (chaque appel récursif se fait sur un successeur du sommet de l'appel précédant). D'autre part, si un cycle est atteint lors du parcours, alors fatalement un des appels récursifs finira par tomber sur un successeur en cours de visite.
Tester la fonction en partant de gag d'indice
0 dans le graphe de dico3court qui ne
contient pas de cycle. Un cycle devrait par contre être détecté
en rajoutant arc d'indice 22 à
la liste de successeurs de guy d'indice 9 :
g.listeSucc[9] = new Liste (22, g.listeSucc[9]) ;
System.out.println (dfsCycle (g, 0)) ;
Modifier la fonction précédente pour que les mots visités soient affichés dans l'ordre inverse d'un tri topologique s'il n'y a pas de cycle, c'est-à-dire que tous les successeurs d'un mot doivent être affichés avant le mot.
Écrire une fonction static void invTriTopologique (Graphe
g) qui affiche tous les mots du graphe g dans
l'ordre inverse d'un tri topologique et qui provoque une erreur si
jamais il y a un cycle.
Modifier un seul caractère de votre programme de sorte qu'un tri topologique soit affiché. (Indice : on ne construira pas forcément le graphe dont on veut afficher le tri topologique.)
Question réflexion : y a-t-il un tri topologique évident pour le graphe orienté ainsi défini sur les mots ?
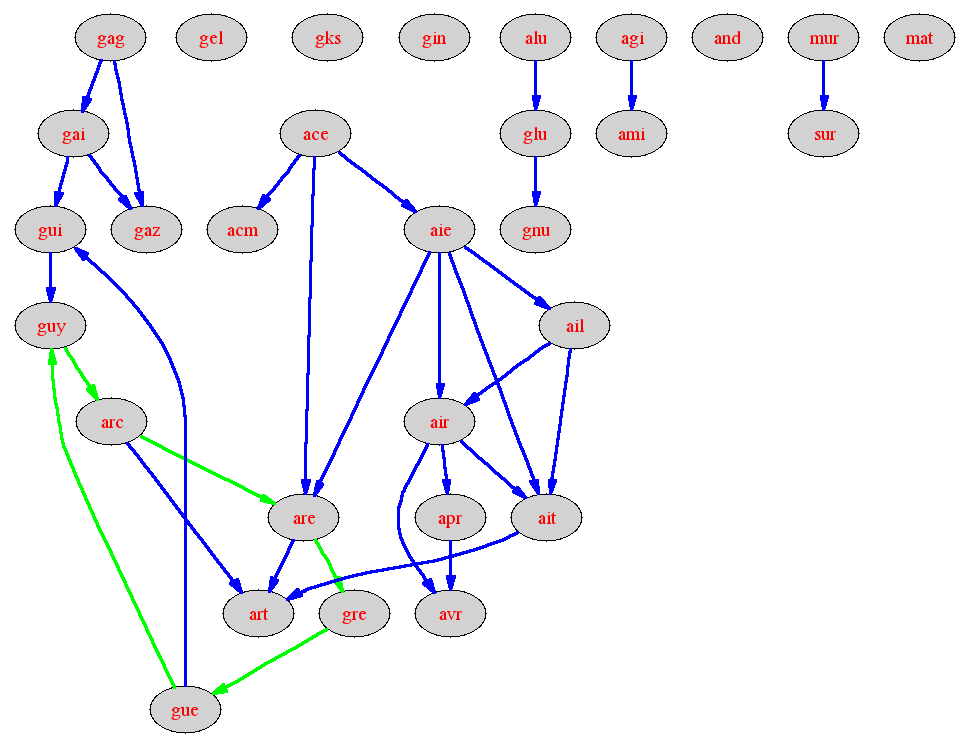
Visualiser avec dot un cycle du graphe
lorsqu'il y en a un. On pourra stocker le fils en cours de visite lors
du parcours en profondeur et
modifier la fonction d'affichage du graphe.
La commande dot
est en effet plus adaptée pour dessiner
des graphes orientés. Attention la syntaxe pour les graphes orientés
(digraph) est différente de celle des graphes non orientés
(graph) : l'orientation des arêtes est signifiée par
des -> à la place des --.
Votre programme doit alors afficher
le graphe sous la forme :
digraph dico {
node [color=red, fontcolor=red, fillcolor=white, style=filled];
edge [style=bold, color=blue];
gag -> gaz ;
gag -> gai ;
gai -> gui ;
guy -> arc [color=green];
...
}
Le rajout de [color=green] derrière un arc
permet d'indiquer à dot de le dessiner en vert
plutôt qu'avec la couleur définie par défaut (bleu).
La suite de commandes suivantes est une manière de
stocker le graphe sorti par votre programme dans un
fichier g.dot (au lieu de l'afficher),
puis d'en faire un dessin
dans un fichier postscript g.ps
avec dot et de le
visualiser avec kghostview :
java Graphe > g.dot dot -Tps g.dot > g.ps kghostview g.ps
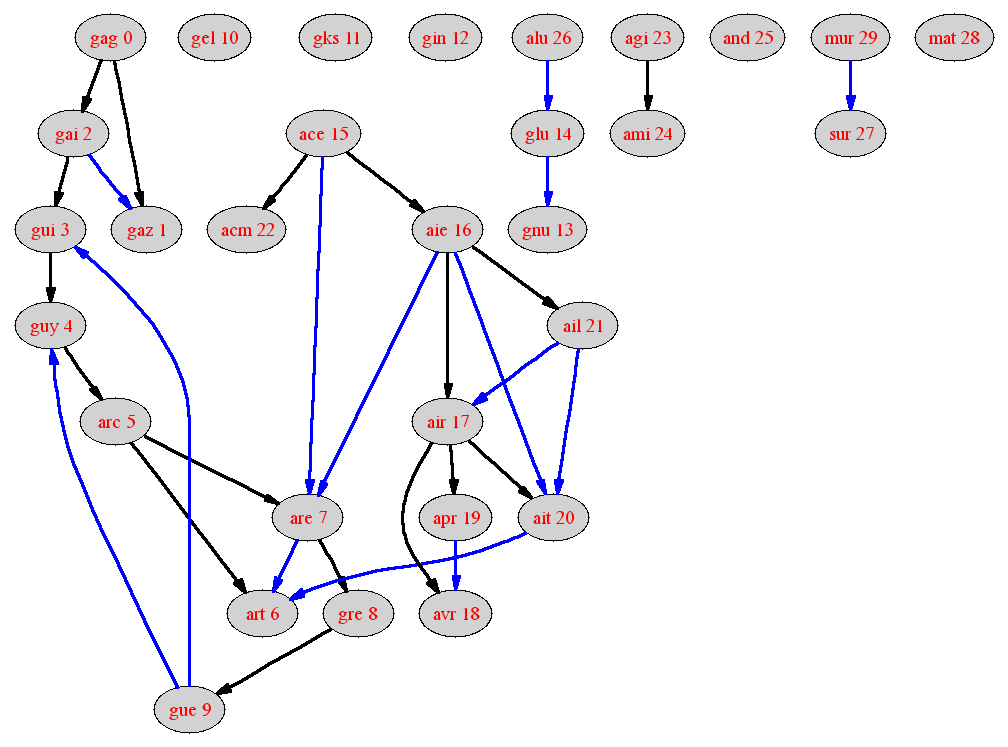
Lors d'un parcours en profondeur, si lors de la visite d'un mot
d'indice x, un successeur d'indice y est vu
par x, on peut définir x comme le père de
y (l'appel récursif sur y a été fait depuis
celui sur x). On obtient alors une arborescence de Trémaux.
Rajouter dans la classe Graphe une variable
pere qui permettra de stocker pour le mot d'indice
i, l'indice pere[i] de son père dans
l'arborescence.
Visualiser l'arborescence de Trémaux produite par un parcours en profondeur. On pourra aussi afficher le numéro de visite d'un sommet avec la syntaxe :
gag [label="gag 0"] ;
Le but dans cet exercice est de calculer les composantes bi-connexes du graphe (non orienté) de la lettre qui saute défini au TD 01. Le calcul des composantes bi-connexes est similaire à celui des composantes fortement connexes et mieux adapté à l'exemple du jeu de la lettre qui saute. Il est important de comprendre pourquoi les propriétés utilisées sont vraies pour bien les programmer, n'hésitez pas à poser des questions.
Reprendre la version non orientée du graphe de la lettre qui saute et le parcours en profondeur tel que programmé dans le TD 01.
Modifier les deux fonctions de parcours en profondeur pour que la
fonction visit calcule pour chaque mot
son numéro et le numéro de son point d'attache.
On stockera ces deux séries de nombres dans deux tableaux.
Rappel : les sommets sont numérotés au fur et à mesure où ils
sont visités. (Le premier sommet visité est numéroté 0, le suivant
1, ...) On appelle ici visite du mot tout ce qui se passe
durant l'appel récursif de dfs sur ce mot.
On supposera qu'un mot est numéroté dès le début de sa visite.
Il faut noter que les successeurs d'un mot visité
sont soit déjà visités soit
visités récursivement durant la visite du mot.
On appelle fils d'un mot, ses successeurs pour lesquels
on fait un appel récursif à dfs.
Le numéro de point d'attache d'un mot est le plus petit numéro
parmi son propre numéro, les numéros de ses successeurs et
les numéros de point d'attache de ses fils. Vu autrement,
le numéro de point d'attache
d'un mot est le minimum de son numéro
et des numéros de
tous les successeurs de tous les mots
visités récursivement pendant sa visite.
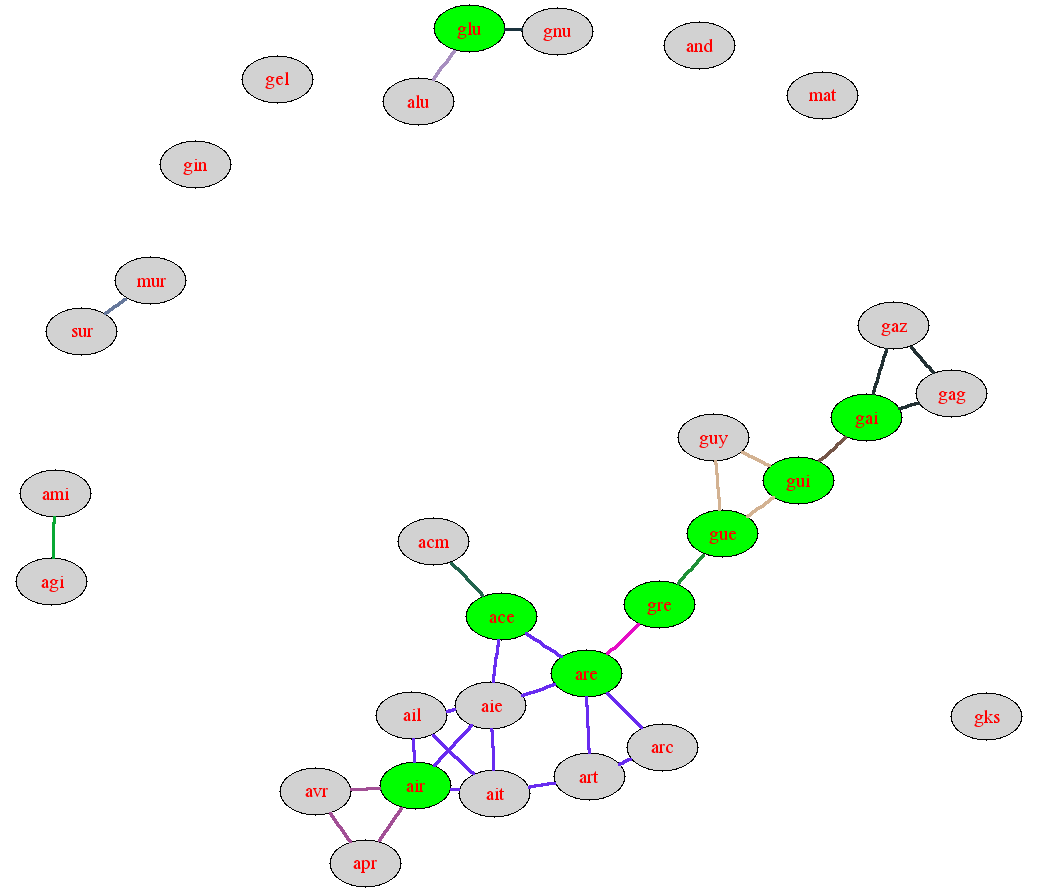
Modifier les fonctions précédentes pour qu'elles affichent les points d'articulation.
Rappel : les points d'articulation sont ceux qui déconnectent leur composante connexe si on les retire. Le mot de départ d'un parcours en profondeur est un point d'articulation s'il a au moins deux fils (en effet, les deux fils seront déconnectés l'un de l'autre si on le retire puisque le parcours récursif sur le premier n'a pas atteint le deuxième). Un mot visité ensuite est un point d'articulation s'il a un fils de point d'attache de numéro supérieur ou égal au sien. Dans le cas non orienté, un sommet a un point d'attache de numéro inférieur à celui de son père puisque son père fait partie de sa liste de successeurs. Un point d'articulation différent du sommet de départ du parcours est donc un mot dont un fils l'a pris pour point d'attache. En effet, si on retire le mot, ce fils sera déconnecté des sommets visités avant le mot puisque le parcours récursif sur ce noeud n'a pas atteint de mot visité avant le mot.
Par exemple, les points d'articulation du
graphe de dico3court sont
ace, air, are, gre,
gue, gui, gai et
glu.
Question réflexion : quels sont
les mot qui apparaissent forcément dans un chemin de
lion à peur connaissant le chemin
lion
pion
paon
pain
paix
poix
poux
pour
peur (calculer les points d'articulation du graphe de
Dicos.dico4 pour répondre).
Le calcul des composantes bi-connexes est similaire à celui des composantes fortement connexes. Nous précisions dans ce paragraphe les similarités et les différences. La principale ressemblance vient du fait que le parcours en profondeur va parcourir les composantes de manière similaire : une fois entré dans une composante, le premier appel récursif va visiter toute la composante. Notons cependant quelques différences fondamentales :
a
et l'arête b >>. (Cycle simple voulant dire que le
cycle ne passe qu'une fois par un sommet donné.)
En outre, un sommet peut appartenir à plusieurs composantes
bi-connexes. Une paire de sommets
successeurs l'un de l'autre identifie donc de manière unique
la composante bi-connexe qui les contient tous les deux.
Modifier les fonctions précédentes pour qu'elles affichent les composantes bi-connexes. Pour cela, remarquons lorsque le premier mot d'une composante bi-connexe est visité, la composante bi-connexe sera entièrement visitée durant les appels récursifs du deuxième mot visité dans la composante (qui sera forcément un successeur du premier mot). En empilant les indices des mots au fur et à mesure de leur visite dans une pile, on peut retrouver les mots de la composante à la sortie de l'appel récursif pour le premier fils dans la composante. (La composante identifiée est donc celle de l'arête reliant le noeud à ce fils.)
Pour le mot de départ d'un parcours en profondeur, on obtiendra une composante bi-connexe pour chacun de ses fils. Pour un mot visité par la suite, on obtiendra une composante bi-connexe pour chacun de ses fils dont le point de d'attache est le mot lui-même.
Pour un sommet donné, on peut détecter plusieurs composantes bi-connexes associées aux arêtes avec plusieurs de ses fils. Il faut donc penser à empiler plusieurs fois le sommet dans la pile au besoin.
Par exemple, les composantes bi-connexes du graphe de
dico3court sont :
apr avr air acm ace ace aie ail air ait arc art are are gre gre gue guy gue gui gui gai gai gaz gag gel gks gin alu glu glu gnu ami agi and mur sur mat
En profiter pour regarder quelles sont les composantes bi-connexes de
lion et peur.
Afficher l'ensemble des arêtes de chaque composante bi-connexe. Le graphe étant orienté symétrique, une arête correspond à deux arcs opposés l'un de l'autre. On pourra empiler les extrémités des arcs rencontrés par le parcours en profondeur de sorte à pouvoir afficher la liste des arêtes de chaque composante bi-connexe (avec deux piles par exemple). Pour ne pas afficher les arêtes en double, on fera attention à n'empiler qu'un seul des deux arcs associés.
Dessiner le graphe des mots avec neato
en faisant apparaître les composantes bi-connexes par la couleur
des arêtes : toutes les arêtes d'une même composante seront
affichées de la même couleur. On pourra aussi afficher les points
d'articulation avec un fond spécial. On peut indiquer à neato
les choix de couleur par des options entre crochets.
On peut indiquer la couleur
de chaque arête par trois réels (le premier code le ton,
le deuxième la saturation et le troisième la luminosité) avec
la syntaxe suivante :
graph dico {
node [style=filled, fontcolor=red];
edge [style=bold];
gai -- gag [color=".1,.5,.6"];
gag -- gaz [color=".1,.5,.6"];
gaz -- gai [color=".1,.5,.6"];
gai -- gui [color=".2,.5,.6"];
gui -- guy [color=".3,.5,.6"];
guy -- gue [color=".3,.5,.6"];
gue -- gui [color=".3,.5,.6"];
gue [fillcolor=green] ;
...
}
{kind=link}
{kind=link}
{kind=link}