
| Abstract: nodes and links i.e. HTML documents and URLs are the basic building blocks of the Web. Much has been done to enrich the structure, re-usability, and functionality of these individual building blocks. But the Web can also be regarded as a collection of loosely connected set of rather self-contained hyperwebs. Few efforts have concentrated on augmenting the power of hyperwebs; we believe that typing concepts for such hyperwebs are a key to re-use, structure, and usefulness of Web-based information. The GUTS approach for hyperweb typing will be introduced in this paper, its value for the re-use of Web-based information will be discussed. |
Nodes and links (together with anchors) are the atomic constituents of hypermedia documents - for the Web, the most important such constituents are HTML pages (or HTML documents) and URLs. "The Web" can be regarded as a world-wide coherent set of such nodes and links, growing almost in anarchy without rules. This paper concentrates on a structural entity that lies in between the atomic constituents and the global transitive closure that we call "the Web": a meaningful, coherent set of nodes and links. Before hypermedia went global with the Web, the notion of hypermedia documents as self-contained sets of nodes and links was much more common than the idea of links that would lead from one such document to another (note that, e.g., the term "Web site" refers not only to a physical location i.e. computer in the Internet where "some nodes and links" reside: quite often a "site" is viewed as a logically correlated set of nodes and links, too). We will refer to such a logically coherent set of nodes and links as "a hyperweb" in the remainder, in contrast to "the Web" as the set of all hyperwebs (note that hyperwebs may contain hyperwebs in a hierarchical manner).
In the context of the workshop, we want to advocate typing concepts for hyperwebs which cover both structural and logical aspects. We believe that the re-use of Web information can be sufficiently improved using such concepts, where re-use may refer to the issue of finding information by query or navigation or to the issue of incorporation of Web information into augmented hypermedia; by the latter we mean systems which are built on top of hypermedia-based structured information (such as, for instance, hypermedia-based learning systems, software engineering environments, decision support systems, and many more).
Hypertext Re-Use and Typing Concepts
A) Atoms: Typing for the atomic constituents of hypermedia has been around for quite some time. Even in HTML, there is a primitive form of implicit typing. For nodes, such implicit typing is given via media type and file format (cf. different graphics and video file types); for links, it is given via target node types (local/remote document, "mailto:", etc.). In the context of semantic networks, it is common to classify the atoms into (usually disjunct) node and link classes; such classification can be viewed as an explicit, user-defined variant of the implicit typing described before. Attributes supported in many hypermedia systems may be viewed as another primitive form of typing; in HTML, the <meta> tag can provides a means for defining attribute names and values. More advanced hypermedia systems support user-defined types of nodes and links; for some of them, typing is based on the object-oriented paradigm i.e. associated with particular, type-specific operations (methods). User-defined types are often used for modeling the application domain. In open hypertext systems, finally, typing of anchors is crucial for integrating applications (think of, e.g., email subjects, calendar entries, source code lines, etc.).
Benefits for Re-Use: What are the benefits in the re-use context if the atomic constituents of hypermedia are augmented by such typing concepts? As the current emphasis of the Web community on meta data indicates, types serve for classification of elements and facilitate indexing and retrieval of information (and hence, re-use). Typing in the programming language sense (e.g., the object-oriented typing mentioned above) helps to integrate nodes and links into larger contexts in a seamless and consistent way. As a simple example, one might imagine a Web-wide definition of node types which visualize the dynamics of a part of the Internet (performance monitors, visualizations of communication protocols etc.). Any Internet user might then re-use such nodes by combining them into a comprehensive monitor since operations like set_update_interval or start_visualisation were uniquely specified.
B) Hyperwebs: On the atomic level of nodes and links, authors and users of hypertext are concerned with individual units of information (nodes) and individual "hops" between adjacent such units. The hyperweb level adresses the more holisitic question of how to "glue together" (or, respectively, how to consume) a set of nodes which "belong together". On this level, node types and link types are assembled into meaningful larger structures. A primitive typing concept for the hyperweb level can be imagined to consist of classifications of nodes and links plus triples "(node-class)<link-class>à (node-class)", describing how different classes of nodes may be interconnected via (different classes of) links. A next step of sophistication might be the one of entity-relationship-diagrams, where single and multiple in- and outbound connections are discerned. Yet more sophistication than this is desired: as to the "glueing together", hyperweb types should provide means for specifying the "building plan" for the corresponding hyperweb types. This includes "chains" of nodes and links, several links types originating from the same node type, and many other local and non-local rules and constraints. With respect to re-use, it must be possible to map hyperweb types onto existing parts of in the Web, see below.
Benefits for Re-Use: Again, the question of benefits with respect to re-use may be raised. These benefits fall into two different categories:
Up to now, the Web community has concentrated on augmenting the power of nodes and links rather than the power of hyperwebs. Many observations back this claim, some of which are listed below:
THE Guts APPROACH
The Guts approach (generic unified typing system) described here leverages off multi-year research at the hypermedia group of the first author. It is based on two principle approaches:
Principal mechanisms for knowledge representation and inference as used in GUTS were thoroughly studied the fields of semantic networks and graph grammars (see for example [Sowa91] and [Rozen97], respectively). As advocated earlier, the basic underlying data structure is the Graph. Our extended notion of a Graphs called WebStyles comprise a grammar for expressing static (syntactic, structural) and dynamic (semantic, navigational) aspects.
WebStyles
WebStyles are based on previous work about "generic and dynamic aspects of hypermedia" [Richartz96]. They consist of three parts: generic nets, procedures, and rules.
Generic Nets: Generic nets are the core of hyperweb typing in that they describe the essential construction rules for all hyperweb instances that adhere to a considered type. A unique characteristic wrt. the state of the art is the fact that generic nets can themselves be considered hyperwebs. This means that, in order to cope with the generic net aspect of WebStyles, users do not have to learn entirely different paradigms such as PetriNets or algebra. ON the other hand, generic nets exploit some of the functionality found in graph grammars (cf. [Rozen97]) without directly exploiting the burden of their formalisms.
Being hyperwebs, generic nets consist of nodes and links. At the degree of detail discussed in this section, three basic kinds can be distinguished for both nodes and links: mandatory ones, optional ones, and a repetitive kind which will be discussed further below. These kinds are of course orthogonal to the node and link types assigned in the application context. The instantiation of hyperweb types can be considered an evolutionary process which may take the whole lifetime of a hyperweb (cf. "live" documents or hyperwebs representing software, configurations, etc.), Therefore, the type description and the instance "live together", so that instantiated nodes and links can gradually "populate" a generic web. All elements described up to now are depicted in figure 1.
Transformation in generic nets: Apart from the obvious transformations instantiating mandatory nodes and links, instantiating or erasing optional nodes and links two interesting transformations remain from above: instantiating "sequence nodes" and "fan links". The following figures help to clarify how nodes and links can be transformed.
 |
 |
|
 |
|
|
|
|
|
|
|
As figure 2a) indicates, sequence nodes are transformed into "chains" of nodes. Thereby, the link type inbound to the sequence node is inserted between the node instances, and the application-specific type associated with the sequence node is assigned to the node instances themselves.
In figure b) a possible transformation of a fan link is shown. Obviously, fan links expand into "bunches" of links originating from a common source node. The node and link types are assigned as given in the generic net in the obvious way.
Figure c) depicts a section of a generic net consisting of two types of nodes and two types of links. By applying a number of transformation steps, the net shown in d) can be constructed. The example shows that fan links and sequence nodes can be combined in a useful manner: here, the fan link expands into a bunch of links that lead from the initiating node to all the nodes in the chain which results from the sequence node. The optional node outbound to the sequence node gets replicated for all elements of the chain (and has been erased for the topmost node, instantiated for the other two). Note:
Further kinds of nodes/links: Apart from the above-described kinds, alternatives and meta-nodes are supported. Alternative nodes and alternative links are used by the author of a hyperweb to offer a choice from different possibilities during construction. Meta-nodes are used to build recursive and hierarchical structures; thereby, hyperwebs are represented as a single (meta-) node at the next higher level of abstraction. They can help to model complex sub-nets and can be used, e.g., to build tree-like structures. For more detailed descriptions cf. [Richartz96].
Attributes: In the above example according to figure 2d), smart readers might reckon why nodes outbound to a sequence node are replicated for all nodes in the resulting chain quite as well, a single copy (of the node marked as "opt" in the above example) might be kept, with the corresponding link outbound from each node in the resulting chain pointing to that single copy; this is in fact an option, controlled by a specific attribute associated with the links present in generic nets. More generally spoken, each WebStyle object has general attributes, like its node/link type, and more specific attributes, like lower bound and upper bound. The bounds for example are used by the transformations and define how many nodes or links can be instantiated.
Procedures and Rules: Besides default procedures (like isTraversible which tells if an object may be traversed) user defined procedures and rules may be attacheto nodes and links. These procedures and rules may influence the construction of a net even more (e.g. by constraining it) and may influence the navigation in such a net, too.
Ontologies
Knowledge representation involves classifying the things to be represented, e.g. «Mars» is a «planet», «next» is an «order relation», «is a» is a «genus-species relation». Ideally the classes (concepts, types, the terms inside french quotes « ») are explicitly written down and put in relation with each other. This is called a theory, conceptualization, or, as is fashionable, an ontology. (Ontology as a part of philosophy is the study of being, or, the basic categories of existence. With the indefinite article, the term "an ontology" is often used as a synonym for a taxonomy that classifies the categories or concept types in a knowledge base [Sowa91], p. 3)
There are ontologies for everything. For instance, in instructional design, if one wants to use Gagnés events of instruction [GBW92], one could define an ontology containing «gain attention», «indicate goal», «recall prior knowledge», «present material», «provide learning guidance», etc. Or, to be able to talk in terms of Reigeluths elaboration theory [Reigel87], one needs «fact», «concept», «principle», and «procedure».
In these examples we did not consider any relations and formalization of semantics. If one tries to work out these aspects, it soon will be evident that something crucial is missing: How could such an ontology be defined? In which language? Our approach here is to define a kind of "bootstrapping" ontology which built in. Guts representation ontology is rich enough to capture the computational content of new, user defined ontologies. It comprises
A sample re-use case with Guts
To take an arbitrary re-use case for Web-based information, we want to imagine the following: A department of philosophy at a university has texts of relevant philosophers on-line. They want to prepare these texts for re-use by students. A common kind of task assignment lets students create their own philosophical texts, incorporating lines of thought and arguments as developed in the above-mentioned texts.
Now, in order to prepare the on-line texts for re-use, they are to be structured based on semantic networks which describes rhetoric spaces. A corresponding hyperweb type is created; it is based on ideas which have been traditionally used to formalize argumentation. The central concepts are "issues, positions, and arguments (IPA)" for the macro-level (cf. [McCall90] for an elaborate version) and the Toulmin argumentation space for the micro level (cf. [Toul58] for the original reference).
The typing for the entire rhetoric space concept can be best described in a modular way, using a top-level hyperweb and several meta-nodes (as mentioned, these are again hyperwebs). One such meta-node, called issue-space, is depicted in the figure below. It covers the subset of a rhetoric space which deals with a single issue and describes the following reasoning (the terms "node" and "node type" are blurred below for the ease of formulation):
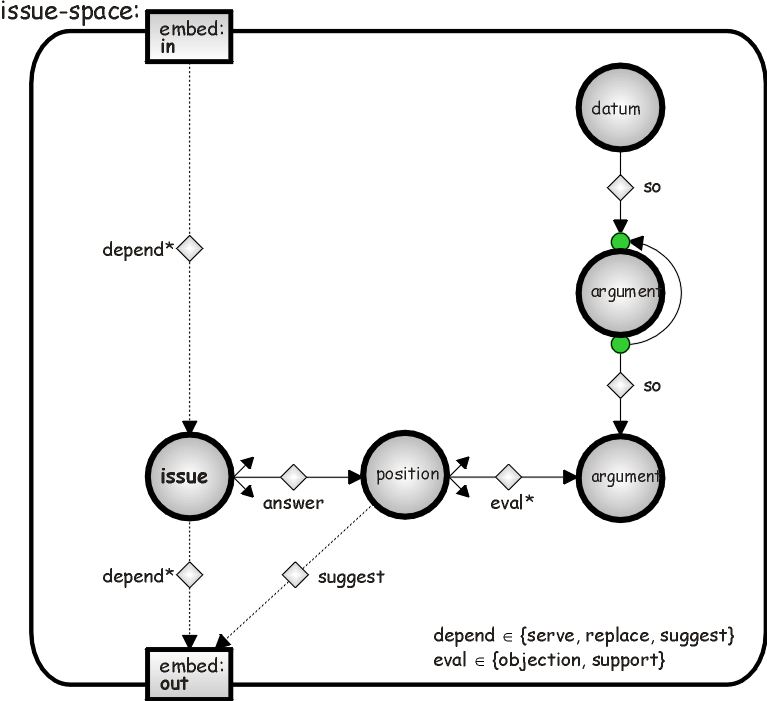
Note that in the above example, we have only considered the "generic net" part of WebStyles for the sake of brevity, neither procedures/rules nor the GUTS ontology/typing aspects. The latter have already come into play since the functionality of WebStyle generic nets is defined using the "bootstrap" typing mentioned above.
In addition, there are aspects of the generic net which we do not want to offer a graphical representation for; the reason is that we want to keep the graphical representation simple, covering the important aspects; additional aspects shall be expressed literally. To take an example, for the last item listed above one might want to make sure that a position may only suggest a "new" i.e. different issue, not the one to which it is an answer. The corresponding type rule reads as follows:
// i1:Issue --[a:Answer]-->
p:Position i2:Issue i1<>i2
// --------------------------------------------------------------------
// p --[s:Suggest]--> i2
The above is to be interpreted as "if there is an answer link a between issue i1 and position p and if i2 is a different issue, then a suggest link s may be created between p and i2. Note that this constraint may be expressed on the higher level of abstract by "forbidding" that an outgoing suggest link of an issue-space may be looped back to its incoming port (in this case, the constraint can in fact be expressed graphically), but the hyperweb type author might as well want to keep this constraint together with the issue-space hyperweb by using the above-mentioned type rule.
Instantiation: reworking the on-line documents now means to create a hyperweb instance which conforms to the type described above; whenever a node (of type issue, argument, position, datum) is created, it has to be mapped onto a portion of the existing HTML document. This iterative process of link-creation, node-creation and content-mapping is driven by the generic web which remains attached to the instance. For each (node/link) creation step, the user has to refer to a "current" node. The core of the system, the so-called "chain-algorithm", then checks which expansions are valid for the current node in the current context. It is this chain-algorithm which enforces conformance to the WebStyle (generic net) and to the semantics of generic nets (i.e., of optional and mandatory nodes and links, sequence links, etc.)
Comparison: Even with the above small example, the reader should have been able to get an idea about relations and constraints that can not or hardly be expressed with other concepts. Meta data embedded in HTML can not even express concepts like fan links; approaches based on triples as mentioned earler can neither express sequence nodes at all nor the effect in the above example that only the last "argument" node in a chain may be an "answer" to a position, etc.
Benefit: Following the example from above, the following benefits become evident. If an on-line philosophical text is re-worked using a WebStyle as was partly described above, several different advantages can be exploited. For one, students can easily create rhetoric spaces and resulting philosophical texts re-using the uniquely represented documents and issue-spaces (which might have been authored in different centuries!). Using an elaborate generic net with additional type rules, the re-working itself may be tightly "controlled" to conform to the WebStyle authors intends. And with rules and procedures added properly, sophisticated navigation and presentation support for the final reader may be prescribed (in a re-usable form) in the WebStyle; to cite just two examples:
WebStyles Implementation and Status
Throughout the past year, two different prototypes have been developed. The first prototype was implemented using JavaScript 1.1. JavaScript was chosen because of the following reasons: a) it integrates very well with HTML-pages and b) it enables users to build dynamic HTML on the client side. The JavaScript prototype was capable of dealing with nodes and links, and even implemented the above-mentioned chain-algorithm on a very basic level. The most serious drawback of the prototype was the lack of a proper user interface, so a lot of activities had to be done by hand.
Meanwhile Java was chosen as language for the next prototype. The Java prototype features graphical editing of WebStyle nets (this includes manipulation of the graph structure and the objects) and implements the complete chain-algorithm.
The prototype is conformant to Dexter hypermedia reference model [HS_94] as far as WWW-compatibility allows, and is divided into two main parts: the user interface, basically represented via the Java class WebStyleEditor, and the WebStyle engine. The engine manages the hypermedia objects and provides a well-defined interface. A Prolog interpreter used to evaluate the rules associated with generic nets.
In order to demonstrate the prototype, a small part of a learning-related domain is modeled with the editor. Figure 5a shows a generic net which models the main characteristics of a biography, consisting of an overview node Biography, a node for the birth and an optional node for the death of a person. In addition, a biography contains some major sections (modeled as a sequence node) which can be mapped to major periods in one's life, for example. Each section may have n dates. Furthermore a person may write publications which have n dates of their own.
In figure 5b the net is shown after some transformations: some nodes and one fan link have been instantiated.
 |
 |
|
|
|
Currently work on the prototype is going on. It will be possible in the near future to export HTML pages linked according to the WebStyles. As soon as that is possible, a more substantial evaluation of the system is planned.
References
[FS89] R. Furuta, P. D. Stotts.
Programmable browsing semantics in Trellis. Proc. ACM Hypertext '89, pp.
27-42
[GBW92] R.M. Gagne, L.J.
Briggs, W.W. Wager. Principles of Instructional Design. 4th Edition , Hbj
College & School Div, 1992
[GF92] M. R. Genesreth, R.
E. Fikes et al. Knowledge Interchange Format, Version 3.0 Reference Manual,
Computer Science Department, Stanford University, Technical Report, 1992
[GHM_94] K. Grønbæk,
J.A. Hem, O.L. Madsen, L. Sloth: Cooperative Hypermedia Systems: A Dexter-based
architecture. CACM 37, 2 (Feb. 1994), pp. 64-75. cf. http://www.daimi.aau.dk/~kgronbak/DEVISE/index.html
[HS_94] F. Halasz, M. Schwartz,
The Dexter hypertext reference model. CACM 37, 2 (Feb. 1994), pp. 30-39.
[HTM98] R. Hauber, T. Kopetzky,
M. Mühlhäuser. Lifecycle Support for Hypermedia Based Learning.
Proc. Ed-Media 98, AACE Conference on Educational Hypermedia and Multimedia,
Freiburg, Germany, June 1998 (to be presented).
[LaS98] Lassila, O., Swick, R.
Resource Description Framework Model and Syntax. http://www.w3.org/TR/WD-rdf-syntax
[Lay98] Layman, A. et al. XML-Data.
http://www.w3.org/TR/1998/NOTE-XML-data-0105
[McCall90] R. McCall et al. Phidias:
A PHI-based Design Environment Ingerating CAD Graphics into dynamic Hypertext.
Proc. ECHT '90, INRIA France, Nov. 90, Cambridge University Press, pp.
152-165.
[MM97] A. Mendelzon,
T. Milo. Formal Models of the Web, Prof. ACM Database Systems, Tucson,
Arizona, June 1997.
[Reigel87] C.M. Reigeluth
(Ed.). Instructional Theories in Action. Lawrence Erlbaum Assoc, September
1987
[Richartz96] Martin Richartz.
Generik und Dynamik in Hypertexten. Shaker Verlag, Aachen 1996 (in german)
[Rozen97] G. Rozenberg.
Handbook of Graph Grammars and Computing by Graph Transformation: Foundations.
World Scientific, 1997
[STH97] M. Salampasis, J. Tait,
C. Hardy. HyperTree: A Structural Approach to Web Authoring. Software
Practice and Experience, Vol. 27(12), 1411-1426, December 1997.
[SF89] P. Stotts, R. Furuta. Petri-net-based
hypertext: document structure with browsing semantics. ACM ToIS 7(1), pp.
3-29
[Sowa91] J.F. Sowa. Principles
of Semantic Networks. San Mateo, 1991
[SRB96] D. Schwabe, G.
Rossi, S. D. J. Barbosa. Systematic hypermedia application design with
OOHDM. Proc. 7th ACM Hypertext '96, pp. 116-128
[Toul58] Toulmin, S. The Uses
of Argument. Cambridge University Press, 1958
[WebSQL] University of Toronto,
http://www.cs.toronto.edu/~websql/