C. A. Lindley, B. Simpson-Young, U. Srinivasan
CSIRO Mathematical and Information Sciences
Locked Bag 17, North Ryde NSW 2113, Australia
Phone: +61 2 9325 3107, Fax: +61 2 93253101
Craig.Lindley@cmis.csiro.au
Bill.Simpson-Young@cmis.csiro.
au
Uma.Srinivasan@cmis.csiro.au
The FRAMES Project within the Advanced Computational Systems Cooperative Research Centre (ACSys CRC) is developing technologies and demonstrators that can be applied to the reuse, or multi-purposing, of video content using the World Wide Web. Video content is modeled in terms of several levels of filmic semantics including a combination of automatically detected video and audio characteristics (eg camera motion, number of speakers) integrated with higher level, authored semantic interpretation models. Active processes for searching semantic descriptions expressed at these different levels can then be accessed either by direct query over the web, or using virtual video prescriptions containing embedded queries that are routed to the FRAMES database system by a virtual video engine.
Accessing video content on the web today is limited to watching pre-prepared video clips or programs and, in some cases, having random access within that footage. Random access is normally provided by the use of slider bars but can also be facilitated by hyperlinks from key frames or textual references. The use of such video material is usually restricted to that explicitly intended by the service (ie sequential viewing of prepared video material) and does not facilitate the reuse of this material by other applications and for other purposes.
Issues that need to be addressed to ensure that video resources on the web are reusable include copyright issues, conventions with regard to video metadata, standardised transport and streaming protocols, and protocols for other types of access to the video (eg getting single frames or getting specific macroblocks from a compressed frame of video to assist in motion analysis). Effective modelling of video content is another key requirement supporting reuse by high level description. A lot of recent research has led to the development of commercial tools for similarity-based retrieval of images and video by matching a prototype object or feature specification against similar features of database media components (eg. IBM, 1998). However, the similarity of visual features is not adequate in itself for generating novel and coherent video montage sequences having specific higher level meanings. This paper presents an architecture currently under development that addresses this need by integrating low level feature models with high level models of objects, events, actions, connotations, and subtextual interpretations of video sequences. This type of modelling aims to ensure that the presentation of pieces of raw footage is not restricted to a single program about a single topic but can occur as part of a huge number of different programs over time. This paper gives an example of such reuse in the form of a virtual video generation system that makes use of the models of video content.
Previous work within the ACSYS CRC has developed the Film Researchers Archival Navigation Kit (FRANK) demonstrating remote web-based search and retrieval of video data from video archives (Simpson-Young, 1996). The FRANK system was based on searching and navigating through textual representations of video material, specifically transcripts and shot lists, and providing a tight integration between text-based navigation and the navigation through the video. The FRAMES project within the Advanced Computational Systems Cooperative Research Centre (ACSys CRC) is now developing an experimental environment for video content-based retrieval and dynamic virtual video synthesis using archival video material. The retrieval and synthesis is supported by rich and structured models of video semantics. The generation of dynamic virtual videos is based upon multi-level content descriptions of archived material, together with a specification of the videos that are to be created expressed as a virtual video prescription (a document created by an author that provides characteristics and constraints of the virtual video that is to be produced).
This paper describes the semantic metamodel that FRAMES uses and the proposed FRAMES architecture. The paper then describes the processes used to generate dynamic virtual videos based upon prescriptions and content descriptions.
The FRAMES system will initially be trialed using client software at the Sydney site of the CRC (the CSIRO Mathematical and Information Sciences Sydney laboratory) remotely accessing video archives at the Canberra site of the CRC (on the Australian National University campus). In this case, the bandwidth available will be adequate for VHS-quality video. It is expected that the architecture and technology developed in this Extranet setting will later be applied both to low bit-rate video over typical Internet connections and to broadcast quality networked video. The technology may be applied to stand-alone dynamic virtual video systems, to intranet systems accessing internal corporate video databases, or to internet technologies to provide remote and interactive access to on-line video databases.
A video semantics metamodel is the core component of the FRAMES system. Based upon the film semiotics pioneered by the film theorist Christian Metz (1974), we identify five levels of cinematic codification to be represented within the metamodel:
The connotative and subtextual levels of video semantics have generally been ignored in attempts to represent video semantics to date, despite being a major concern for filmmakers and critics. Modelling "the meaning" of a video, shot, or sequence requires the description of the video object at any or all of the levels described above. The different levels interact, so that, for example, particular cinematic devices can be used to create different connotations or subtextual meanings while dealing with similar diegetic material.
Metamodel components are drawn upon in the FRAMES authoring environment in order to create specific models, or interpretations, of specific video segments. There may be more than one model at any particular level, for example, corresponding to different theories of subtext or created by different people. Cinematic and perceptual level descriptions may be generated automatically to an increasing extent. Subtextual and connotative descriptions are necessarily created by hand; in the FRAMES system this will be done using a structured GUI interface to an object relational database. The diegetic level represents an interface between what may be detected automatically and what must be defined manually, with ongoing research addressing the further automation of diegetic modelling (eg. Kim et al, 1998). While low level models can be created automatically to some extent, higher level descriptions created by authors both facilitate and constrain the use of specific video segments in automatically generated dynamic virtual videos. Hence high level annotation should be regarded as an extension of the authoring activities involved in film and video making to the dynamic, interactive environment.
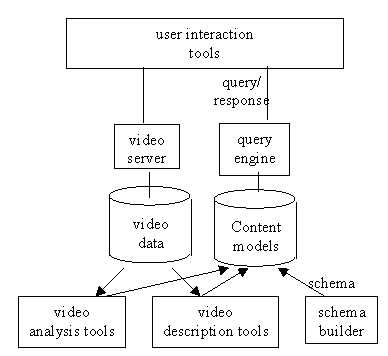
Figure 3 shows the core FRAMES architecture. From the point of view of reusability of web resources, the major components in this architecture are the query engine and the video server. Each of these can be independently accessed over the Internet for specific applications (eg the video server can be accessed directly for sequential playback of stored video and the query engine can be used for querying a video database returning links to offsets into specific video content). However, these components demonstrate their full power when combined and when used together with applications such as that discussed in the next section.
Figure 1. Core FRAMES Architecture.
The query engine is located behind an HTTP server and receives a query (which uses an XML query language) from the client using the HTTP POST method. The engine queries the content models (using methods described in the next section) and returns a list of hits, each of which gives references to specific video content (including location of the footage and start and end offsets) and metadata associated with a particular piece of footage (such as copyright information etc). This list would be in one of the following formats depending on arguments in the request:
The content models themselves are currently implemented as object-relational models under an Object Relational Database Management System, and the query engine uses SQL queries, either directly or to implement an Application Program Interface (API) for the association engine (see next section).
Although the query engine and content models can be used directly for search and retrieval of video content, the important point, with regard to reuse of the content, is that it can also be used for a wide variety of other purposes, for example, virtual video generation.
Virtual videos can be specified by an author in the form of virtual video prescriptions (Lindley and Vercoustre, 1998). These are based on the concept of virtual document prescriptions (Vercoustre and Paradis, 1997, Vercoustre et al, 1997). The first version of the FRAMES dynamic virtual video synthesis engine, currently under development, will support three methods by which video segments may be retrieved and inserted within a dynamic virtual video stream:
Specific filmic structures and forms can be generated in FRAMES by using particular description structures, association criteria and constraints. In this way the sequencing mechanisms remain generic, with emphasis shifting to the authoring of metamodels, interpretations, and specifications for the creation of specific types of dynamic virtual video productions.
Figure 2 shows the FRAMES architecture with the additional of the virtual video engine.
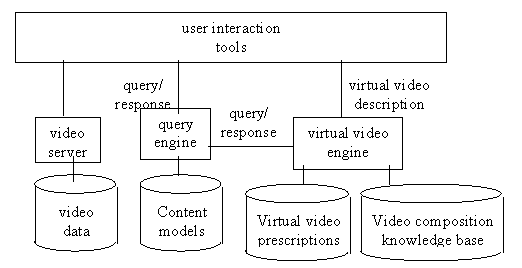
Figure 2. FRAMES Architecture showing virtual video production..
The virtual video engine is also located behind an HTTP server. It receives a set of parameters from an HTTP POST message, selects a virtual video prescription accordingly and resolves the prescription by satisfying the constraints given by the parameters. There are two general cases of virtual video generation: a) non-interactive virtual videos; and b) interactive virtual videos. In the case of non-interactive virtual videos, the virtual video prescription is fully resolved into a virtual video description (Lindley and Vercoustre, 1998). The virtual video description takes the form of an XML document that is sent back to the client. Virtual video descriptions use the same XML DTD as virtual video prescriptions but are a special case in that all queries have been resolved to specific video data addresses. For interactive virtual videos, a users interactions dictate the direction the video takes (as in Davenport and Murtaugh, 1995), so each user interaction results in new requests being made resulting in virtual video description chunks being continually sent to the client.
For video content on the web to be reusable, there need to be rich models of the video content at several levels of semantic codification, and these models need to be accessible on the web independently of the video content itself. We have discussed the FRAMES system which uses an architecture that facilitates reuse of video data by using mulit-level semantic models for the generation of virtual videos from underlying databases and video archives. This architecture operates through the world wide web, allowing video material to be incorporated into new and dynamic productions from diverse and distributed sources.
Aigrain P., Zhang H., and Petkovic D. 1996 "Content-Based Representation and Retrieval of Visual Media: A State-of-the-Art Review", Multimedia Tools and Applications 3, 179-202, Klewer Academic Publishers, The Netherlands.
Davenport G. and Murtaugh M. 1995 "ConText: Towards the Evolving Documentary" Proceedings, ACM Multimedia, San Francisco, California, Nov. 5-11.
IBM 1998 QBIC Home Page, http://wwwqbic.almaden.ibm.com/stage/index.html.
Hoschka P.(ed) 1998, "Synchronised Multimedia Integration Language" W3C Working Draft 2-February 1998 (work in progress).
Kim M., Choi J. G. and Lee M. H. 1998 "Localising Moving Objects in Image Sequences Using a Statistical Hypothesis Test", Proceedings of the International Conference on Computational Intelligence and Multimedia Applications, Churchill, Victoria, 9-11 Feb., 836-841.
Lindley C. A. and Vercoustre A. M. 1998 "Intelligent Video Synthesis Using Virtual Video Prescriptions", Proceedings of the International Conference on Computational Intelligence and Multimedia Applications, Churchill, Victoria, 9-11 Feb., 661-666.
Metz C. 1974 Film Language: A Semiotics of the Cinema, trans. by M. Taylor, The University of Chicago Press.
Murtaugh M. 1996 The Automatist Storytelling System, Masters Thesis, MIT Media Lab, Massachusetts Institute of Technology.
Simpson-Young B. 1996 "Web meets FRANK: Tightly Integrating Web and Network Video Functionality", AusWeb'96, Gold Coast, July '96. http://www.scu.edu.au/ausweb96/tech/simpson-young
Simpson-Young B. and Yap, K. 1996 "FRANK: Trialing a system for remote navigation of film archives", SPIE International Symposium on Voice, Video and Data Communications, Boston, 18-22 November.
Simpson-Young B. and Yap K. 1997 "An open continuous media environment on the web", AusWeb-97.
Srinivasan U., Gu L., Tsui K., and Simpson-Young W. G. "A Data Model to Support Content-Based Search in Digital Videos", submitted to the Australian Computing Journal, 1997.
Vercoustre A-M. and Paradis F. 1997 "A Descriptive Language for Information Object Reuse through Virtual Documents", in 4th International Conference on Object-Oriented Information Systems (OOIS'97), Brisbane, Australia, pp299-311, 10-12 November, 1997.
Vercoustre A-M., Dell'Oro J. and Hills B., 1997 Reuse of Information through Virtual Documents, Proc. of the 2d. ADCS Symposium, Melbourne, Australia, April 1997.