1. Introduction
As the popularity of the Internet explodes, many suppliers of electronic components have found it compelling to publish product information on the Web. Their customers have also found it easier to obtain up-to-date product information directly from the Web. Electronic publishing of product information on the Web is expected eventually to replace the use of printed datasheets for electronic components [Rom97].
Electronic publishing further opens up an opportunity for corporate procurement organizations to streamline the production and use of their Component and Supplier Management (CSM) databases. A CSM database contains parametric information about components so that electronic design engineers in the company can search for suitable components via a structured query based on the properties of components, and corporate procurement personnel can better control and qualify the supply chain. CSM databases have traditionally been maintained manually by procurement librarians who are experts in the product domain. The librarians extract information about the components from printed datasheets or data books, transcribe the information into the format and terminology prescribed in CSM, and enter the extracted information into the CSM databases.
While electronic publishing of datasheets or data books makes it possible to obtain product information directly from the Web, it does not eliminate the need for a CSM database. Electronic datasheets are available on the Web as unstructured text, and the essentially keyword-based search capability existent on the Web cannot offer answers to queries such as "Find the flash component on the market with cycle time no greater than 120ns and availability within 2 weeks." However, with electronic publishing of datasheets, there is now the potential of largely automating the extraction process, thereby reducing the cost of CSM database maintenance, and significantly increasing its timeliness and quality of service. The CSM database can also become an active component of the CSM function, facilitating discovery of new components, suppliers, and supply chain dynamics, and leading to a transformation of the CSM function itself.
In this paper, we describe the Component Advisor, an on-going research project in extracting structured, parametric information about electronic components from datasheets published on the Web. The project is conducted as part of the Web Content Mining research effort at HP Labs, whose goal is to build intelligent Web mining agents. While we have chosen electronic components to be our initial domain, we postulate that the results can also be applied to other product domains.
Our approach is based on modeling domain knowledge, and using this to focus the work of the mining agent. We structure the domain model to consist of vendor-neutral knowledge about products and the conceptual structure of documents (datasheets), which is fairly regular within the industry, and knowledge that is specific to particular vendors’ datasheets. Our hypothesis is that our model-based approach, which exploits regularity within a domain, is more scalable and resilient to changes than format-based approaches that required detailed modeling of individual documents. A prototype mining agent has been implemented in Java and Perl, and will be experimented with extensively to validate our hypothesis.
In the longer term, parts of the domain knowledge may actually be updated or discovered by the mining agent as it roams the Web to extract information.2. Related Work
Web content mining has received considerable attention lately, and many efforts have been reported; we briefly review some of these efforts below.
In the mediator architecture [Wie92], site-specific wrappers provide integration of information from heterogeneous databases; as the architecture is applied to integrate Web contents, wrappers become extraction procedures for documents on a Web site. Several techniques to build wrappers have been reported in the literature. Feature extraction techniques offer useful operators but do not tend to take advantage of domain knowledge. For example, in [HGCAC97], a method for feature extraction based on a set of text operators is proposed. Each text operator takes a text variable as input and assigns the resulting text to another text variable. Feature extraction consists of manually constructing an extraction script composed of these operators.
Other techniques attempt to automate, to different degrees, the generation of wrappers. [AK97] describes a method for semi-automatically generating wrappers based on heuristic rules. The idea is to exploit the formatting information from the source to hypothesize the hierarchical underlying structure of the page. NoDoSe [Ade97] is an interactive tool for semi-automatically determining the structure of documents and extracting their data. The user hierarchically decomposes the document and maps it to a previously defined structural model of the document. The task is expedited by a mining component that attempts to infer the grammar of list and record types from the user input. In [KWD97] a system to automatically extract data from Web pages is described. The data must be represented as a set of tuples; no deep structure is inferred. A machine learning algorithm infers the grammar of a document from a set of instances of the document type. It uses domain knowledge in the form of oracles that can identify interesting types of fields within the document.
The previous approaches make important contributions to the field; however, a limitation that they have in common is that they are too format dependent. The wrappers are based on the exact format of the Web document at a very fine level of granularity. Wrappers must be regenerated each time the format of the page changes, which happens often. Format independent approaches that overcome this limitation are needed.
Several shopping agents have been proposed [DEW97, Bar, KRU97]. A shopping agent is capable of collecting from the Web simple parametric information, such as price and availability, about products in a specific domain, and presenting the comparison information to the user. So far these efforts have been deployed in domains such as personal software and music CDs, using the search forms provided by the vendors to obtain the information; [DEW97] incorporates vendor form-learning logic. However, complex text documents such as datasheets have not been dealt with in these efforts.
Commercial CSM vendors, such as Aspect Development [Asp] and IHS Engineering [IHS], still rely primarily on a manual approach to collect and update information in their component databases. Data interchange standards are being proposed [ECIX], but they are not expected to be adopted widely in the short run. Web content mining, in the meantime, holds considerable promise for streamlining Component and Supplier Management.
3. Domain Model and Vendor Catalog
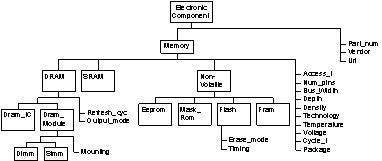
Two types of knowledge drive the Component Advisor, vendor-neutral and vendor-specific. Vendor-neutral knowledge is captured in the domain model and consists of two parts. The product concept model describes the product family including the hierarchy of product types as well as their characteristics. Figure 1 shows this for memory components. Each characteristic is modeled by a set of attribute-value pairs. The values of some attributes are the keywords that usually accompany the specification of the characteristic, like label and unit. The other attributes are the data type and constraints on the value of the characteristic. Besides the product family itself, the documents containing the product specifications -- datasheets in the electronic component domain -- also need to be modeled. This is done in the document model which describes the structure of the document in terms of its sections, along with the relationships between sections and product characteristics. This is shown in Figure 2 for memory datasheets. Regularities exhibited by the documents are also captured in this model to provide more hints for the identification of relevant data. In datasheets for example, it is common to find a specific formatting structure, like a table or a list, for a particular section.
Figure 1. Product Concept Model: Memory.
Vendor-specific information such as home page URL, vendor specific terms (synonyms for those in the domain model), various indicators on the organization of the site, and so on, is captured in the vendor catalog.
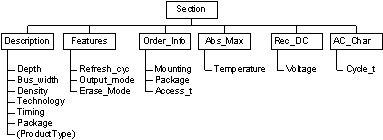
Figure 2. Document Model: Memory Data Sheet.
4. General Architecture
As stated in Section 1, the objective of the Component Advisor is to provide design engineers with up-to-date information about electronic components. This is done by a mining agent back end which mines the Web for component data in batch mode. Its tasks are to find the URLs of the product datasheets and analyze them to extract useful data. This data is then loaded into a database to be queried by design engineers through a browser-based front end. Figure 3 illustrates the general architecture of the Component Advisor.
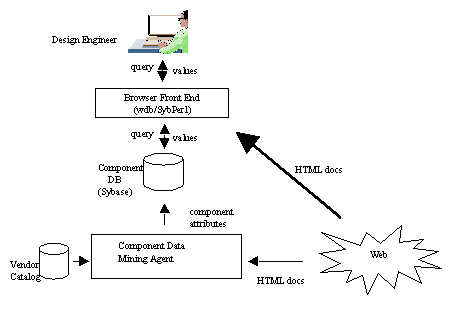
Figure 3. General Architecture of the Component Advisor.
More specifically, given the name of a manufacturer and its URL as input, the mining agent navigates through the pages of the manufacturer’s site to find the right page for the product family in order to obtain the URLs of the datasheets of individual products. Once the corresponding pages are retrieved, their contents are analyzed to identify and extract the relevant information. The navigator and the extractor, shown in Figure 4, respectively perform these two tasks. The loader (not shown here) takes the extracted data and loads it into the database. The whole process is under the supervision of the controller which invokes the appropriate system component at the right time.
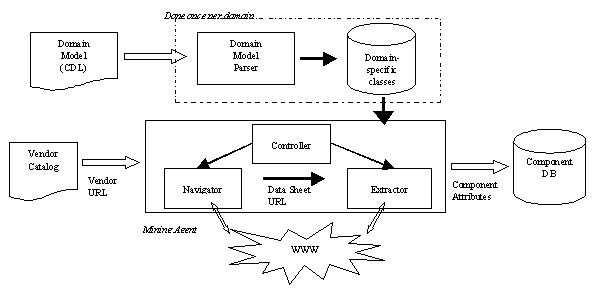
Figure 4. Mining Agent Architecture.
4.1 Navigator
Given the starting URL for a vendor’s Web site it is the job of the navigator to find the datasheets for that vendor’s components. Generally, the starting URL for a vendor will be the one for the vendor’s home page, but it need not be. Navigating from the starting URL to the vendor’s datasheets involves either following promising links (link-based navigation), or filling out search forms and submitting them (form-based navigation), or a combination of both.
We have broken down the navigation process into a series of actions to be performed. The first action is to retrieve the vendor’s starting Web page, which is done by the visitor module. The next action is to perform pattern matching on the Web page to locate either links to follow or forms to fill out, which is the job of the pattern matcher module. In the case of form-based navigation, the form filler module is called next to fill out the form, followed by a call to the form submitter module which submits the form to the search engine of the vendor. The results of the search that are returned by the vendor are then analyzed by a link analyzer module to determine whether these are the expected search results, i.e., a list of references to datasheets.
The challenge lies in determining which are the promising links to follow and which are the right forms to fill out. Backtracking may be necessary if a link or a form leads to a dead end. Once the navigator has found all datasheets for a given component family, the list of datasheet references is passed to the extractor for extraction of the component data.
4.2 Extractor
The extractor performs an iterative process on the list of datasheet references that the navigator obtained. For each datasheet, the extractor sequentially invokes different functionalities provided by its various modules. First, the visitor module retrieves the datasheet from the URL specified in the reference. The extractor then proceeds to analyze the Web document guided by the domain model. The product concept model is consulted for the description of the product type in terms of its characteristics. The datasheet structure is obtained from the document model, as well as the relationships between document sections and characteristics of the product.
By knowing in which section a characteristic is located, a section recognizer module is invoked to identify the portion of the document corresponding to that section. This can be done either by looking for a table of contents in the datasheet and obtaining the URL reference of the section, or by performing a search guided by heuristics to identify the section header in the document. Once the section is identified, a structure recognizer module has the task of recognizing the formatting structure specified for that section in the document model. Finally, a pattern matcher module is invoked to find the value of the characteristic.
In the product concept model only the keyword elements surrounding the specification of a characteristic’s value are defined. The idea behind this is to make possible the use of different techniques for the matching. The simplest one is to build regular expressions from the keywords, but at the cost of becoming dependent on the format of the text. Other more sophisticated techniques which make distance measurements can be used. In this way, if the matching fails with one technique, it is still possible to try another one. The architecture is extensible with respect to the sets of pattern matchers and structure recognizers.
The process is repeated iteratively for each characteristic to be mined from the datasheet. As the values are extracted they are written to a file in a specific format. Finally, when the extraction process on the datasheets of the vendor is completed, the file is passed to a loader to be loaded into the database.
5. Implementation and Discussion
The Component Advisor is implemented in Java using JDK 1.1. Those parts of the system that deal with pattern matching are written as Perl scripts. These scripts are called from Java using the Runtime and Process classes.
During implementation we uncovered a number of issues. One of these is poorly written HTML. For example, we encountered structures such as tables which are not defined with the appropriate HTML tags. This complicates the recognition of structures, in particular the identification of tables and their elements as well as the correlation of elements with the corresponding column headers. Another issue is that many datasheets are available only in PDF format and the HTML output generated by current PDF to HTML converters is poor at best. Datasheets and components may lack one-to-one correspondence, i.e., there may be one datasheet for multiple parts or multiple revisions of a single datasheet, complicating the extraction process. We also found a need to extend our domain model to cover such things as attributes whose value is derived from the values of other attributes.
When dealing with forms, we found that for some vendors the URLs returned in the search results are volatile, i.e., they become invalid after a short period of time. This required us to change the operation of the extractor so that these URLs are processed before they expire.
Before processing a datasheet, the extractor makes a pass through the HTML to normalize the text. For example, commas in numbers are removed, special characters, such as the degree symbol, are replaced with a sequence of standard characters (degC in this case), and number words are changed to their corresponding digits. The extractor also flattens table structures before extracting component information from them.
So far we have concentrated on extracting component information from one prominent vendor’s Web site. The prototype system runs successfully for memory component families such as DRAM, SRAM and non-volatile memories. For 172 DRAM datasheets it took the navigator approximately 1.5 minutes to navigate and the extractor approximately one hour and eleven minutes to extract the data. For 46 non-volatile memory datasheets it took the navigator 30 seconds and the extractor 20 minutes. This translates to approximately 2.5 datasheets per minute or about 25 seconds per sheet. This is unoptimized performance.
The operation of the Component Advisor is currently sequential; that is, the navigator finishes before the extractor takes over. One of the areas we want to investigate is the parallel operation of the navigator and the extractor and its effect on performance. It may also be possible for the extractor to do data extraction in parallel. Another area to investigate is the extraction of non-parametric attributes such as part footprints or schematic symbols.
6. Summary
This position paper describes Component Advisor, a prototype mining agent for extracting and reusing information from documents on the Web. The approach is based on modeling domain knowledge, separating vendor-neutral knowledge from vendor-specific knowledge, and using this model to direct the mining agent. We believe that this approach is more robust than format-based approaches that try to wrap each individual document or web site. We have partially validated the approach via a prototype implementation. Ongoing research is aimed at extending and refining the approach to assess how it will scale to a large number of vendors and product families. We are also interested in understanding how well the approach will carry over to other domains.
References:
[Ade97] | Adelberg, B., "NoDoSe -- A tool for Semi-Automatically Extracting Structured and Semistructured Data from Text Documents". Northwestern University Computer Science Department of Computer Science, http://www.cs.nwu.edu/~adelberg/index.html. |
[AK97] | Ashish, N., and Knoblock, C.A., "Semi-automatic Wrapper Generation for Internet Information Sources," Proceedings of the Workshop on Management of Semistructured Data, pp 10-17, Tucson, Arizona, May 1997. |
[Asp] | Aspect Development Inc., http://www.aspectdv.com |
[Bar] | BargainFinder Agent, Anderson Consulting, http://bf.cstar.ac.com/bf/ |
[DEW97] | Doorenbos, R.B., Etzioni, O., and Weld, D.S., "A Scalable Comparison-Shopping Agent for the World-Wide Web", Proceedings of the First International Conference on Autonomous Agents, Marina del Rey, CA, 1997 |
[ECIX] | Electronic Component Information Exchange, Silicon Integration Initiative. http://www.cfi.org/ |
[HGCAC97] | Hammer, J., Garcia-Molina, H., Choa, J, Crespo, A., Aranha, R. "Extracting Semistructured Information from the Web", Proceedings of the Workshop on Management of Semistructured Data, pp 18-25, Tucson, Arizona, May 1997. |
[IHS] | IHS Engineering Inc., www.ihs.com |
[Kru97] | Krulwich, B., "Automating the Internet: Agents as User Surrogates". IEEE Internet Computer 1(4), pp 34-38, 1997. |
[KWD97] | Kushmerick, N., Weld, D.S.,Doorenvos, R., "Wrapper Induction for Information Extraction", Proceedings of IJCAI, 1997. |
[Rom97] | Romick, P., "The Information-Gathering Process for the Wired Engineer". Electronic Design, pp 61-65, January 6, 1997. |
[Wie92] | Wiederhold, G. "Mediators in the architecture of future information systems." IEEE Computer, March 1992. |